NLP 自然语言处理模型在当今科技领域扮演着至关重要的角色。
NLP 自然语言处理模型之所以备受关注,是因为它们能够让计算机理解和处理人类语言,从而实现各种智能化的任务。
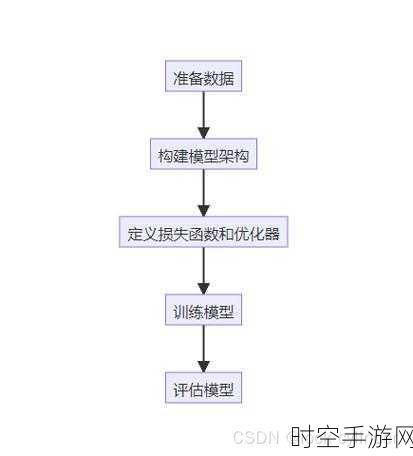
NLP 自然语言处理模型种类繁多,其中较为常见的有基于规则的模型、统计模型和深度学习模型。
基于规则的模型依靠人工编写的规则和模式来处理语言,这种模型的优点是具有较高的可解释性,但缺点是规则的编写需要耗费大量的人力和时间,而且难以覆盖所有的语言情况。
统计模型则是通过对大量的文本数据进行统计分析,来学习语言的规律和模式,隐马尔可夫模型和条件随机场等都是常见的统计模型,这类模型能够处理较为复杂的语言现象,但对于一些罕见的语言情况可能表现不佳。
深度学习模型是目前 NLP 领域的主流,如卷积神经网络、循环神经网络和 Transformer 架构等,深度学习模型具有强大的学习能力和表示能力,能够自动从海量数据中提取特征和模式,从而实现非常出色的语言处理效果,基于 Transformer 架构的语言模型在机器翻译、文本生成等任务中取得了显著的成果。
不同的 NLP 自然语言处理模型各有优劣,在实际应用中,需要根据具体的任务需求和数据特点来选择合适的模型,随着技术的不断发展,新的模型和方法也在不断涌现,为 NLP 领域带来了更多的可能性和挑战。
文章参考来源:相关学术研究及技术资料。